QR Code Patching
QR patching strikes back in CDDC 2023 Qualifiers

Overview
As part of the DSTA BrainHack CDDC Qualifiers, we are given another file patching QR Code challenge. The last time we did one was 2 years ago in Stack the Flags 2020. Whilst solving it this time, I couldn’t help but feel annoyed that we forgot how we solved it last time around. So here I am, documenting this so we can fix corrupted QR Codes in future! (though it probably doesn’t happen frequently)
Initial Steps
Although the challenge has QR Code in its name, we are given a docx file titled Confidential.docx.
We can’t simply open it as it is corrupted. As per standard CTF practice, we rename it with a .zip extension and extract the files. Since we are looking for a QR code, we go straight to the media folder and are met with 2 files image1.png (which only says “confidential”), and Core Code.png.
File Patching
Attempting to open Core Code.png results in an error, indicating that the file is corrupted and we need to fix it.
PNG Format Recap
If you are not familiar with the PNG file format and patching, this is a brief primer.
- Other than the standard file header and footer, PNG Files are made of chunks
- PNG chunk has the following format:
- Length of Chunk Data (4-byte)
- Chunk Type (4-byte)
- Chunk Data
- Cyclic Redundancy Check (4-byte)
- Must contain an IHDR chunk to determine its dimensions and metadata
- Must end with an IEND chunk which is a series of 8 bytes with no chunk data
You can read more at http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
Analysis
We open the corrupted PNG in a hex editor and immediately notice the first chunk is an sRGB chunk (highlighted) with extra data even before the 4-byte chunk data length.

We also notice there is no IHDR chunk. Referring to the chunk specifications, an IHDR chunk should have 13 bytes. There’s 17 bytes of extra data. This includes the 4 bytes of CRC so we can guess this is the IHDR chunk without the IHDR chunk type and chunk data length. Furthermore, we notice the part for width and height is 00 00 01 4A 00 00 01 4A which indicates equal height and width - properties which are characteristic of QR codes.
We also remember that the PNG file needs to have and IEND chunk which does not exist in this file. The last chunk is an IDAT chunk. Based on the 4-byte chunk length indicated right before the IDAT chunk type, the chunk data is 0x6B4 bytes long.
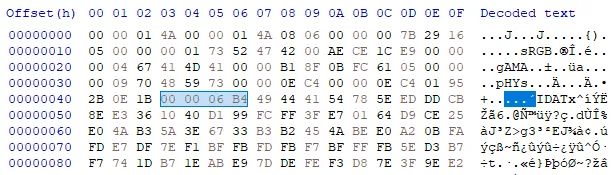
If we count the 0x6B4 length and include the 4 bytes of CRC, we end up at address 0x702, leaving 4 bytes of unknown data 00 00 00 00. These 4 bytes can be the length of IEND data (Recall the IEND chunk has no data). However, omitting this length should still result in a parsable png
Solution
To solve this, we take the following steps:
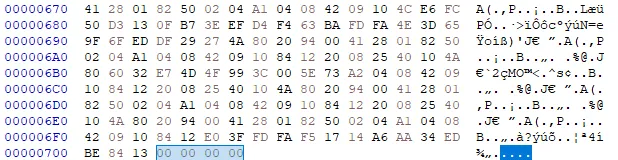
- Insert the 8 bytes of PNG file header + 4 bytes of IHDR chunk length + 4 bytes of IHDR chunk types at the beginning of the file
89 50 4E 47 0D 0A 1A 0A 00 00 00 0D 49 48 44 52
- Append IEND chunk / 8 bytes of file trailer
49 45 4E 44 AE 42 60 82
This gives us a PNG that we can open and we are presented with an incomplete QR code where some areas are redacted in white. The iconinc positioners at the corners have also been removed.
QR Code Recovery
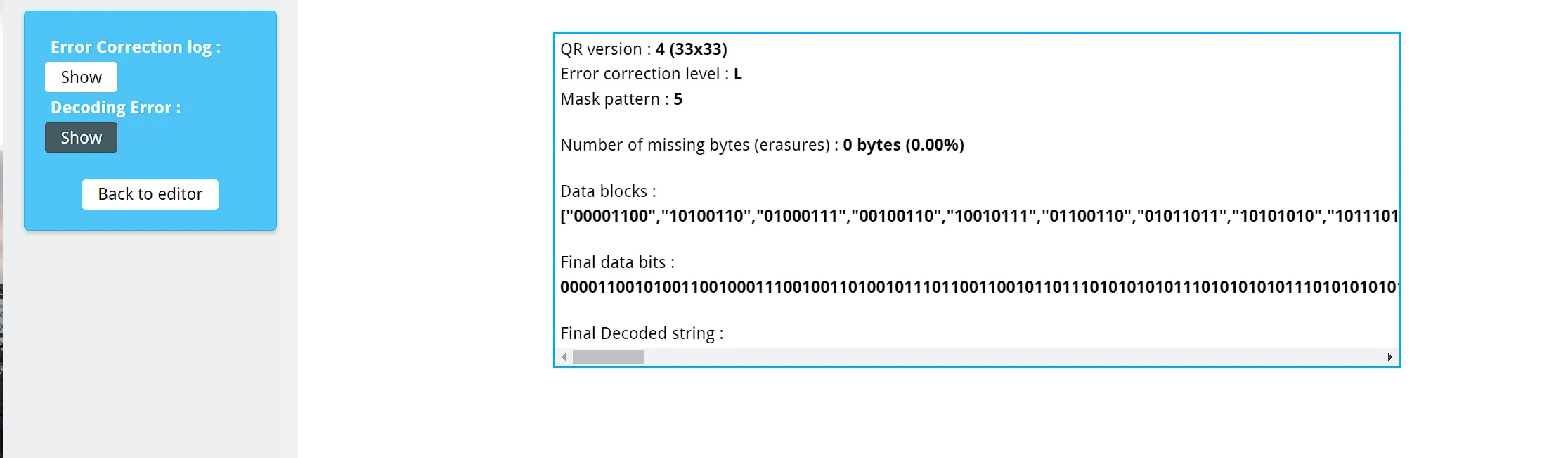
In order to succesfully import our QR code into a QR code recovery tool like https://merri.cx/qrazybox/, I first drew in the positioners using PowerPoint (don’t judge XD).

Then from tools > Extract QR Information, I force extracted the data bits.
If we directly convert the final data bits we get gibberish, but when we remove the first 4 bits, we get the following string:
Êdriveº«ªº«¤e.com/fi`¥/d/1Qj8Nn4gGXF tRqw6lYKi5EyTT7HZHTbr/view?usp< haring
This appears to be a Google Drive link. But brute forcing the missing space did not work.
The steps that follow were done by @WealthyTurtle and @OceanKoh
Analysis
Using the editor we can extract a few pieces of information.
- Version 4
- Error Correction (EC) Level L
- Mask 5

Hence we deduce that
- There should only by 80 data cells and 20 EC cells
- Most of the data cells are intact which gave us the almost coherent text above
With some overlaying and drawing, we determined where the data cells ended, and which data cells were were missing. Technically, if we had all the data cells, the EC cells do not matter.

Playing around with the QR code editor in those data cells, we narrowed our search space for the Google Drive link
Solution
While most teams did a distributed brute force on Google Drive to prevent rate limiting, we instead went with a more deterministic solution. We opted to generate QR codes with the above parameters (using this library by nayuki) until the result matches the EC cells.
import string
from qrcodegen import *
orig = [
'#######__###__#___##____#_#######',
'#_____#____##____##_#___#_#_____#',
'#_###_#__###__#_#____#_##_#_###_#',
'#_###_#_#_####___#_#___##_#_###_#',
'#_###_#_#_#_#___###_#__#__#_###_#',
'#_____#__##___#_#_#__##___#_____#',
'#######_#_#_#_#_#_#_#_#_#_#######',
'_________#_#__###___#___#________',
'##___###_##_###__###__#_____##___',
'__________##___##__#_##____####__',
'______#__#__####______#__##_####_',
'__________##__##___##___##_##___#',
'______#__##_#_##_#_#__##_###____#',
'__________##_####_##__###_##___##',
'______#__##__###____###__##_#__#_',
'____________#__##__#__##_#__#__##',
'______#___######_#__#_####_##___#',
'___________#__####_##__##_##____#',
'______#____###_#####___##_##____#',
'__________###_#_#_____#___###___#',
'______#___#__####___###_##_##____',
'___________#_______#__##____#__#_',
'______#__#___#_#______#___#____#_',
'_________#__#_#___##__##_#_#_____',
'______#__####___##_#_#__#####___#',
'________#__#__#_#___###_#___#___#',
'#######_##__#__#_____#_##_#_#__#_',
'#_____#_#_#_#_###_#___#_#___#____',
'#_###_#__#_###__###_###_#####___#',
'#_###_#___##_##_#__##__###__#____',
'#_###_#____#_#_##__##___##__#____',
'#_____#_#________________________',
'#######_#________________________']
def textify(qrcode: QrCode):
"""Prints the given QrCode object to the console."""
a = []
for y in range(0, qrcode.get_size()):
row = ''
for x in range(0, qrcode.get_size()):
row+="_#"[1 if qrcode.get_module(x,y) else 0]
a.append(row)
return a
def check(arr):
for i in range(20,28):
for j in range(9,11):
if arr[i][j]!=orig[i][j]: return False
return True
charset = string.ascii_letters+string.digits+'-_'
for a in charset:
for b in charset:
for c in 'GF':
for d in '67':
text = 'drive.google.com/file/d/1Qj8Nn4gGX'+c+a+'tRqw6lYKi5EyTT'+d+b+'ZHTbr/view?usp=sharing'
segs = QrSegment.make_segments(text)
qrcode=QrCode.encode_segments(segs,QrCode.Ecc.LOW,mask=5)
qrtext = textify(qrcode)
if check(qrtext): print(text)
Running this code gives us this Google Drive link which contains the flag:
https://drive.google.com/file/d/1Qj8Nn4gGXGXtRqw6lYKi5EyTT7JZHTbr/view?usp=sharing
Flag: y0u_c@n_r3c0v3ry_qrc0d3!